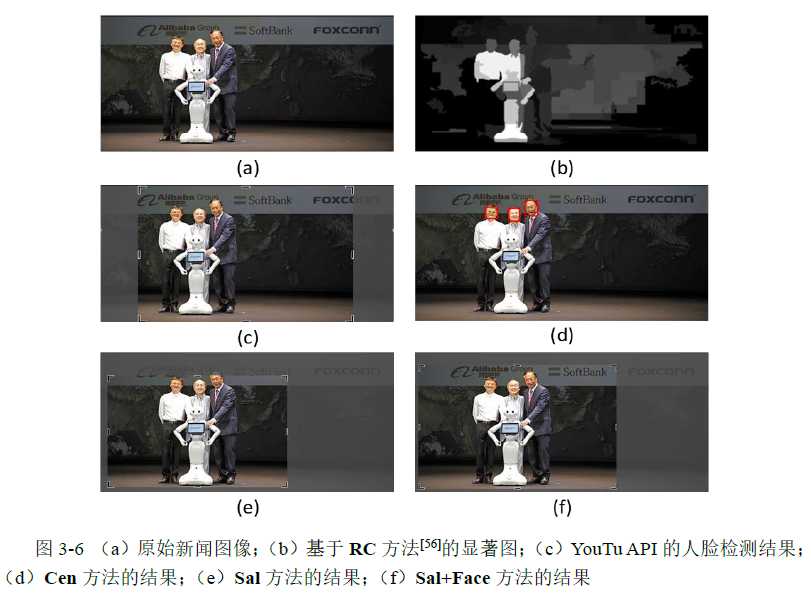
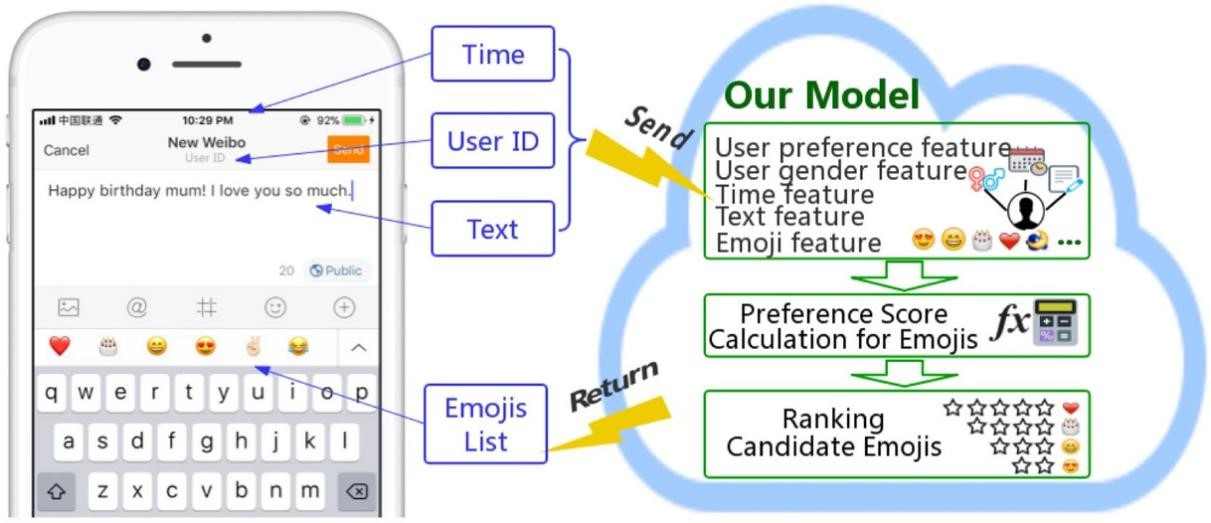
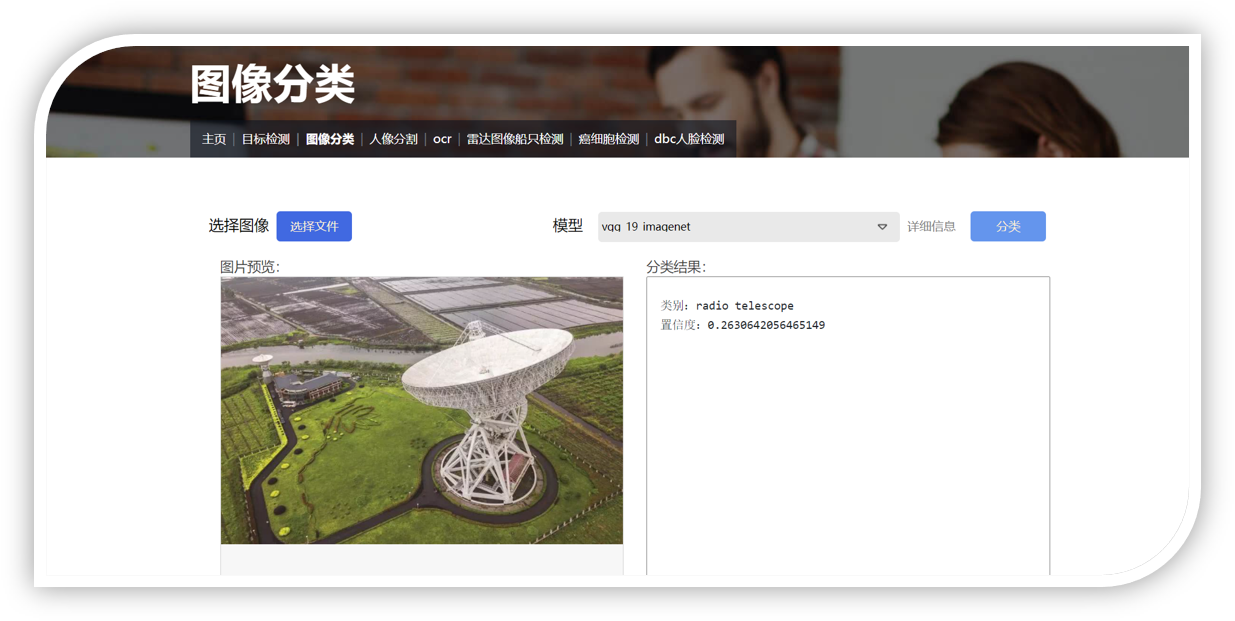
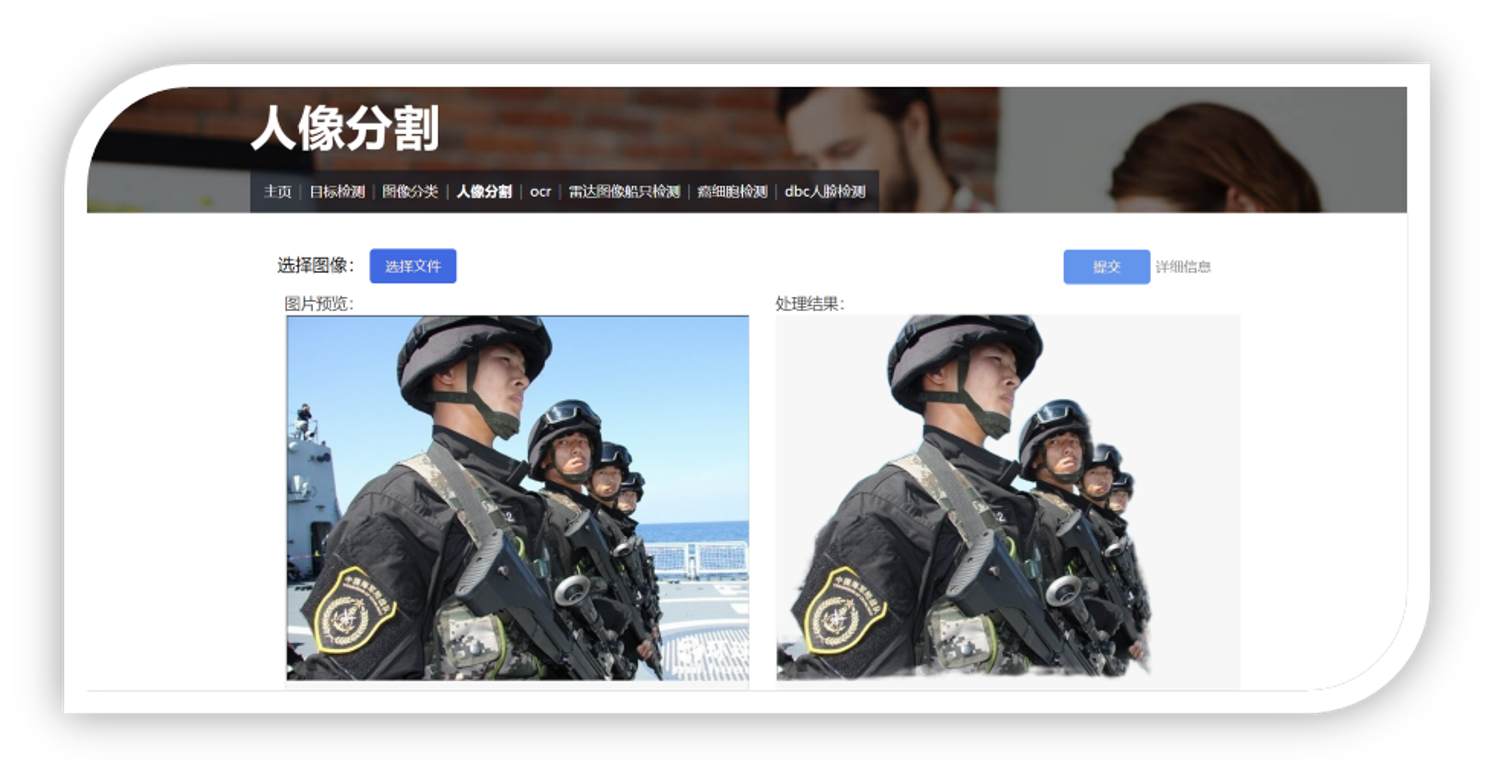
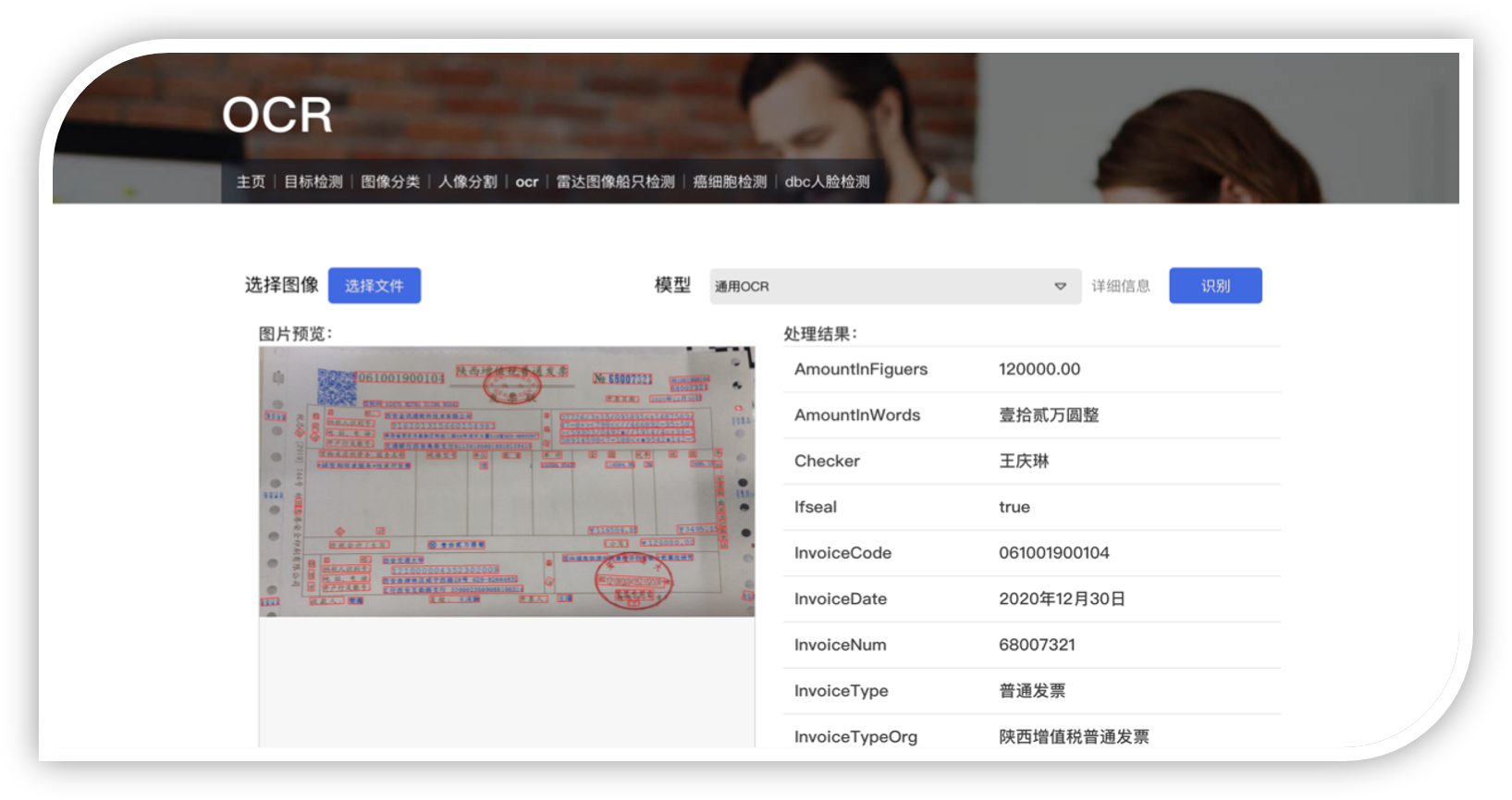
车厢智能分析系统
摘要:
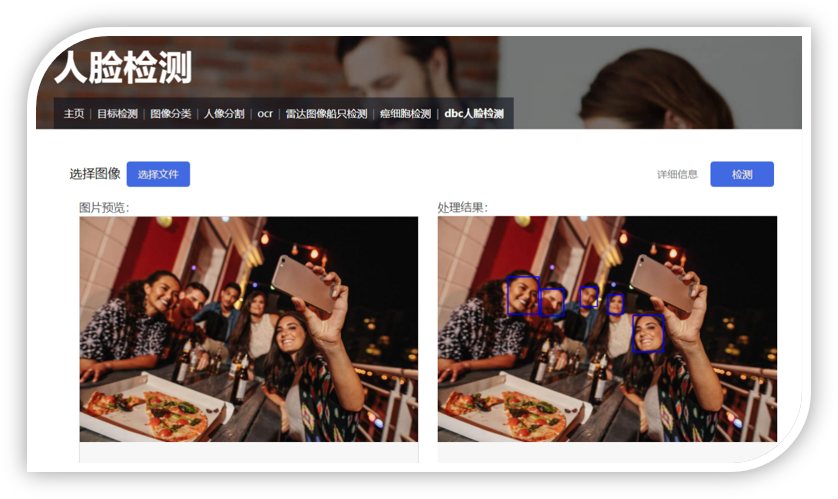
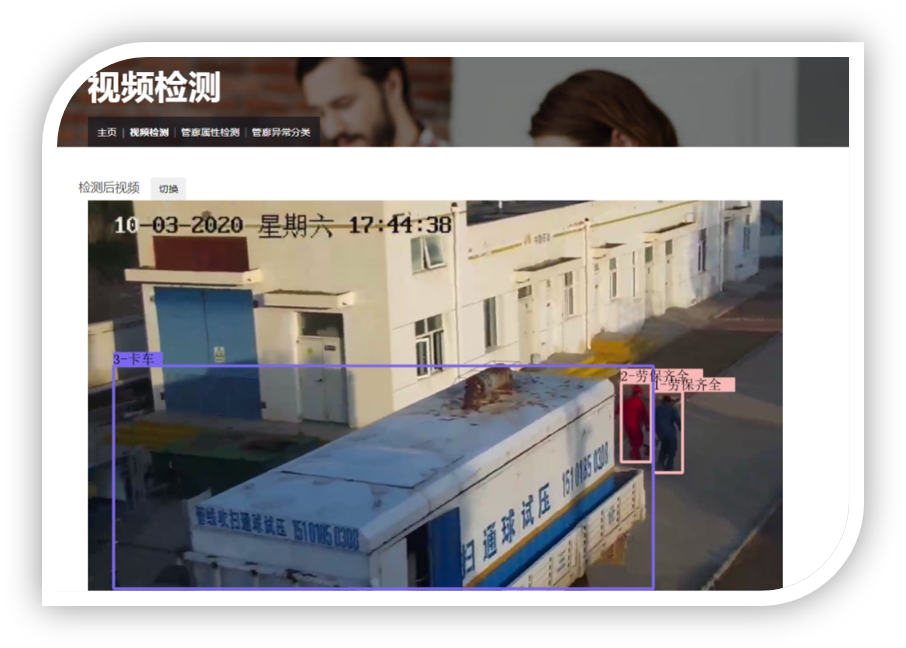
车厢智能分析系统是部署在RK3588芯片上的高准确度、高实时性的综合型视觉系统,目前搭载在高铁车厢的机柜中,已经在中车CR450列车组试运行。 系统分为乘客计数、行李遗留检测、监控屏异常检测、乘客异常行为分析等多种功能。其中,客室内乘客通过摄像头捕捉实时画面进行检测,统计出监测范围内的人员数以及口罩佩戴情况。 车厢通过台中的乘客通过跟踪算法进行统计,实现了较高准确性。同时在列车运行时还会进行监控屏异常检测和乘客异常行为分析,保障列车安全运行。 在列车到站后,全车开启行李遗留检测,完成对列车内乘客物品的清理。以上所有的功能都通过TCP和UDP报文进行通信。
巡航弹目标跟踪系统
摘要:
这是和205所合作的安装的巡航弹上用来跟踪目标的算法,用来对选定的目标进行跟踪,主要包括两个难点:目标遮挡(第一个视频)尺度变化大(第二个视频)
单目标跟踪部分:
为了保证跟踪速度和鲁棒性,我们使用simases孪生网络作为我们跟踪模型,他通过模版匹配的原理进行跟踪,对于各种目标都非常具有鲁棒性。 对于目标遮挡问题,我们通过模版匹配的置信度进行判断是否被遮挡,如果置信度低于一定的阈值则利于卡尔曼滤波的方式进行运动轨迹的更新,并且此时不再更新模版图像。 对于尺度变化的问题,我们设置了三种不同尺度的搜索区域用来和模板图形的特征进行匹配,选择匹配度最高的搜索区域的尺度更新目标框的大小和位置。 最终部署在海思3519上可达24FPS
目标遮挡:
尺度变化:
火花检测系统
摘要:
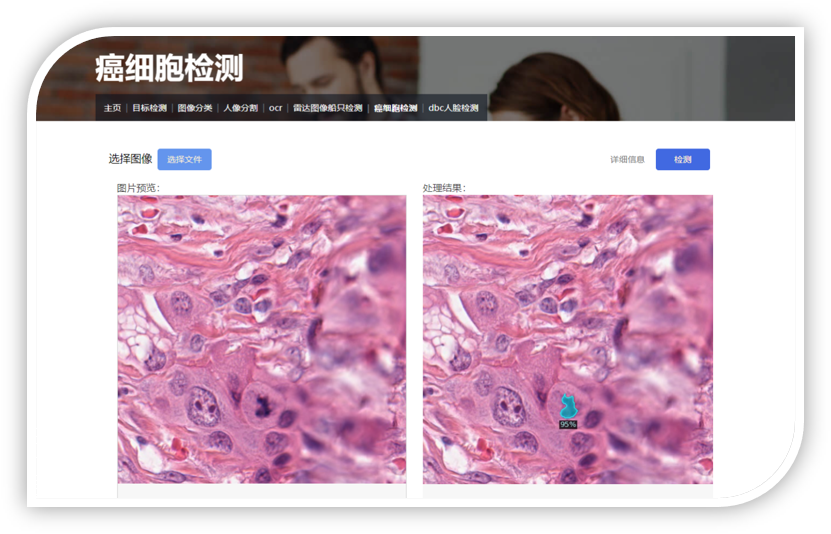
使用500万像素的摄像头,对受电弓的状况进行检测。 将五种算法部署至国产芯片Rknn3588,实现火花检测,结构检测,异物检测,模糊检测,场景检测。 火花检测尤为重要,在列车运行中,火花比较常见,如果火花过大可能会导致受电弓断裂,列车供电会受到影响。火花检测的难点是检测的实时性与准确性兼得,因此我们对模型进行了剪枝量化等操作,在保证实时性的同时保证准确度。 在检测过程中,太阳光与火花容易混淆,产生误报。我们优化了算法,即可以检测阳光,又可以检测火花,降低了误报率。
摘要:
保障行人安全是道路交通安全系统的重要目标之一,这使行人检测作为驾驶辅助系统(advanced driver assistance systems,ADAS)中的核心组成部分。其中获取准确的行人距离十分关键,对此本系统在行人检测模型的基础上加入了行人距离预测分支,提出了一种基于车载视频的行人检测与测距方法,在使用单目摄像头的情况下,可以在检测行人的同时完成对行人与摄像头之间距离的预测。下图为行人检测测距系统流程示意图:
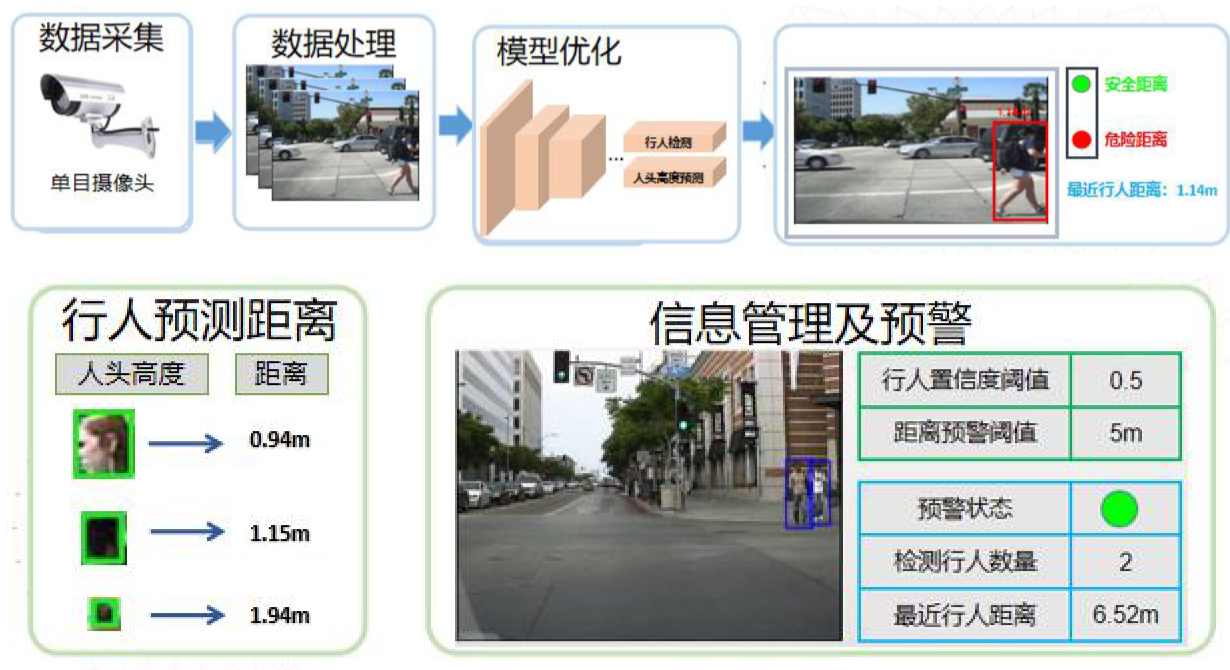

同时,本课题将该模型部署到了基于树莓派 3B 和 Intel NCS2 神经网络计算加速棒的嵌入式平台上,实现了一个简单的行人距离预警系统,系统从摄像头或者视频文件读取视频流,当行人距离摄像头的距离过近时,系统发出预警。实际运行结果如上图所示。
方法优点:
安全帽佩戴情况检测
摘要:
在建筑施工现场,为避免建材从高处坠落造成人员伤亡,所有进入施工区域的人都被要求佩戴安全帽。而常有工人不遵守安全规范,摘下或忘戴安全帽,有着严重的安全隐患。本课题组针对这一问题,基于监控视频对建筑工地上人员的安全帽佩戴情况进行检测识别。如图所示,佩戴安全帽与不佩戴安全帽、佩戴其他类型帽,分别以黄色、红色与蓝色框标出。该课题完成了对安全帽佩戴检测的自动识别。课题中采用深度神经网络的方法,对不同类型的带帽人员以及不戴帽人员进行检测和良好的属性区分,方法具有一定的实时性。


优点:
应用及成果: 开发的系统已经在杭州市江干区住建局成功使用。
单菜品属性识别系统
摘要:
本系统通过计算机视觉技术提供了一种菜品食材等属性信息的识别方法。通过对菜品细粒度特征的识别,实现了百种预设菜品的主要食材、菜品口味特色、适宜人群推荐、相似菜品推荐、以及菜系、烹饪方式等属性信息的识别。如下图为自动菜品结账系统系统流程示意图。

优点:
应用及成果: 本项目获微软亚洲研究院 2019 学术日 Real World Scenario Award 奖。
多菜品识别系统
摘要:
本系统实现基于视觉的自动菜品结算系统,通过对菜品种类及食材的识别,获取具体的摄入菜品种类和数量,实现营养成分的估计,提供了一种基于细粒度识别的菜品自动结算及饮食健康管理方法。实现了共计百种食物的识别。如下图为自动菜品结账系统系统流程示意图。
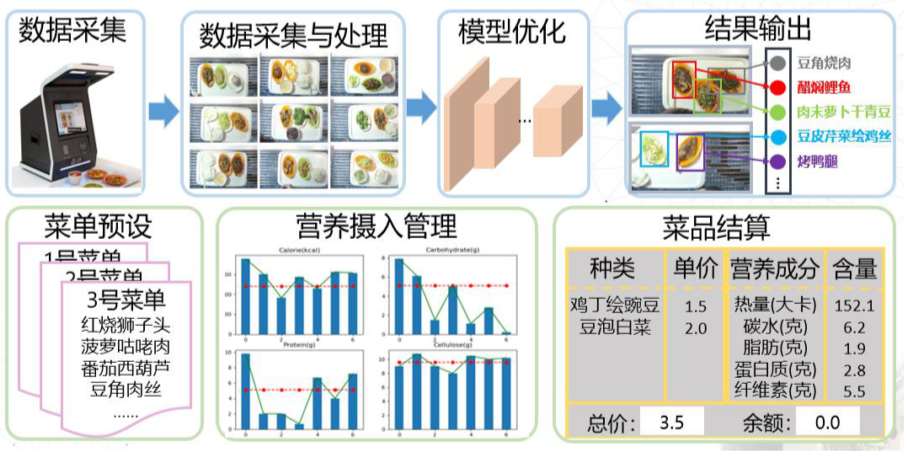
优点:
应用及成果: 钱学明、彭豪、侯兴松、邹屹洋、李纬.一种基于细粒度识别的菜品自动结算及饮食健康管理方法:(专利受理)
货柜商品识别系统
摘要:
智能无人货柜得益于其体积小巧,售卖场景多样、用户购物交互体验强的优点,受到大众的欢迎。摈弃了现有基于计算机视觉技术的智能无人货柜识别商品类目少的缺点。本系统将计算机视觉的检测与检索技术相结合,共同实现了智能无人货柜的近百种商品识别系统。下图为本系统的实现流程示意图。

优点:
应用及成果: 开发的系统已经在山东新北洋信息技术股份有限公司测上线应用。
人员口罩检测(或者特定服饰等)
摘要:
当前我国大范围爆发了新型冠状病毒(2019-nCoV)感染,我们在支持疫情一线的医护人员的同时,也要做好个人的防护措施。其中佩戴口罩对于防止疫情蔓延至关重要,但仅靠人工监督,效率太低且耗费大量人力。本项目基于这个问题,提出了一套对是否佩戴口罩自动检测和预警系统。如下图为口罩检测系统流程示意图。
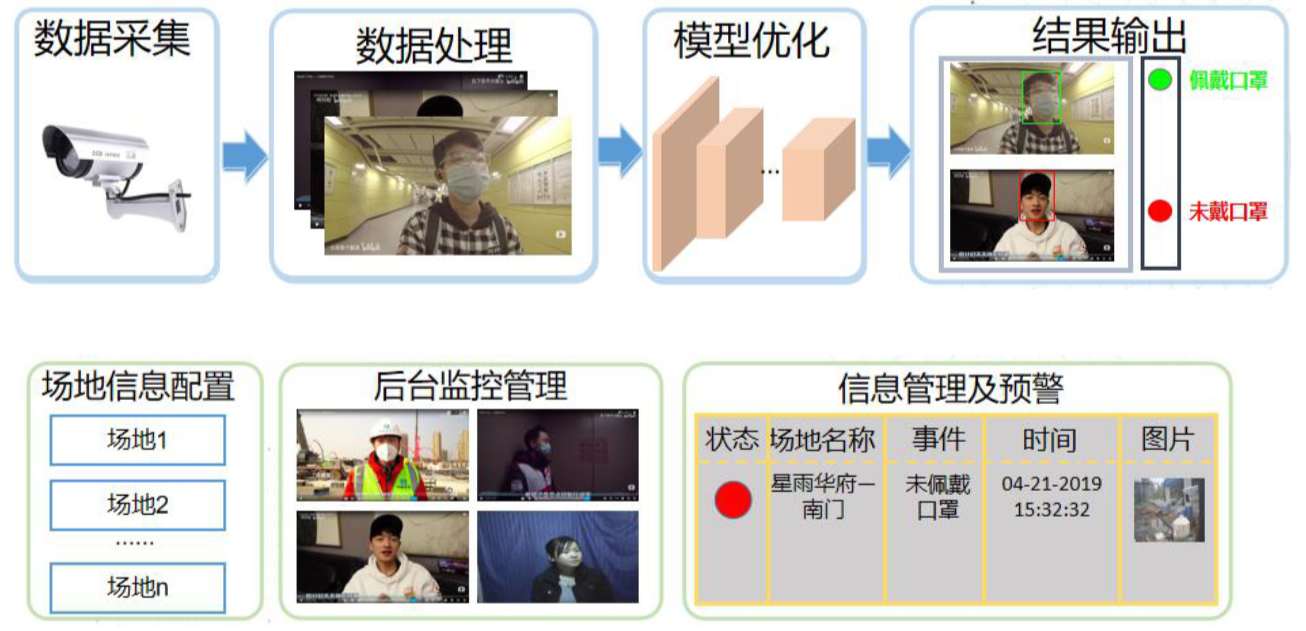
方法优点:
行人检测、检索系统
摘要:
本系统可从监控视频中检测出所有行人,使用截图功能设定目标人物,可自动定位到其他时段出现的该行人。如下图所示,截取行人正面照片,可定位到该行人被监控摄像拍到的侧面以及背影。可以看到,目标人物的其他时间点所拍摄到的照片,均在排列靠前的搜索结果中。该系统中,对象(行人、车辆等)采用深度特征描述,采用特征匹配和搜索的方法,可以在历史数据中找出当前对象相似的目标。

基于司机状态识别的辅助驾驶方法研究
摘要:
本系统对司机状态识别来达到辅助驾驶的功能,通过对司机状态进行拍摄监测,通过检测模型来得到司机实时的面部区域和手部区域,进而对面部区域进行关键点检测和对手部区域进行分心状态识别,从而对司机是否疲劳驾驶和分心驾驶作出判断,并对司机进行提醒预警,起到辅助驾驶的作用。共实现了对司机闭眼、打哈欠两种疲劳状态以及玩手机分心状态的监测,其中,对唇部打哈欠、眼部睁闭眼状态识别的准确率分别达到 99.07%、94.6%。如下图为驾驶员驾驶状态监测系统流程示意图。
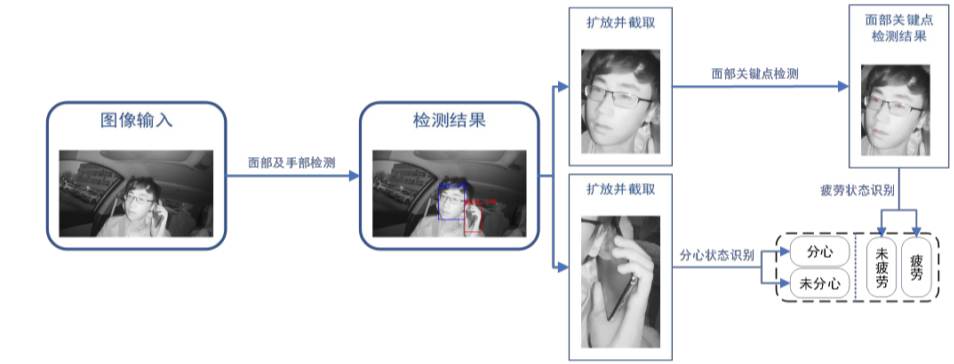
本系统通过对当前摄像头前人物的眼部特征进行监测、处理识别,可判断出其是否处于疲劳状态,演示效果如图所示,右上角概率设为非疲劳的预测值,当人物闭眼时,标记框为红色并报警,当人物睁眼时标记框为绿色,判断其为非疲劳状态。

方法优点:
应用及成果: 该算法可以较好地应用到司机辅助驾驶的功能使用中,来起到事故的主动防御作用,达到更安全的出行。
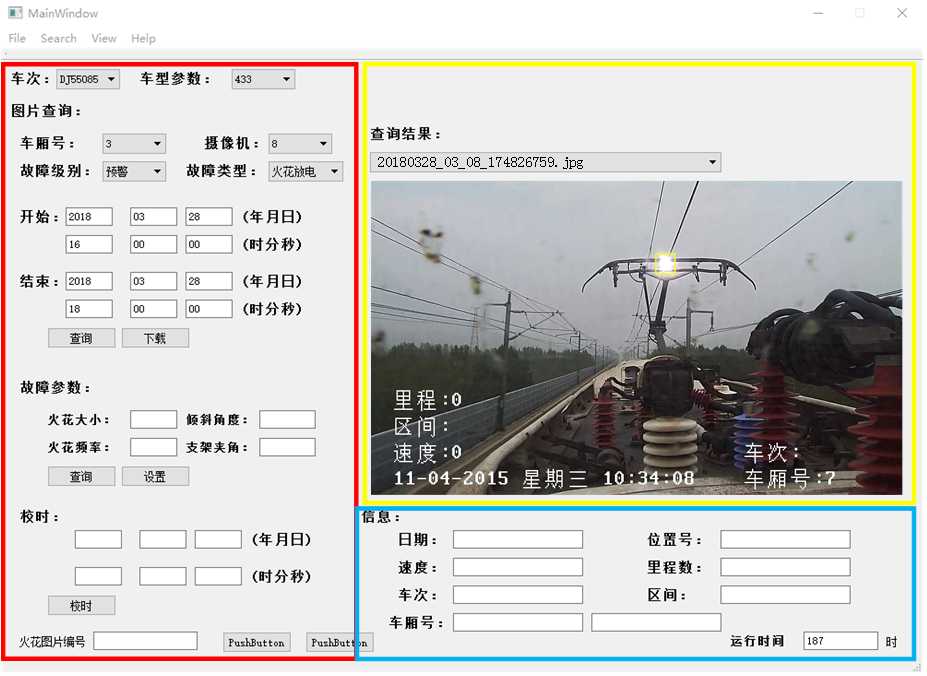
基于AI与大数据学习的高铁受电弓状态监视
摘要:
自动检测受电弓状态、受损情况、弓角异常、打火等及预警。实现满足电车工控机运行条件的可视化QT软件,覆盖实用的基础功能,安装简便,适用简易。
监控视频之对象检测及检索
摘要:
设计算法和应用软件,实现对行人、车辆、人脸等对象的检测和检索。

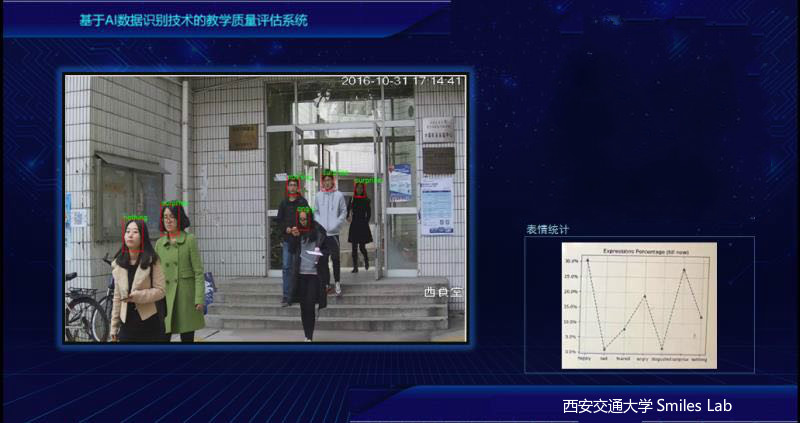
人脸表情分类系统
摘要:
本系统可以从摄像头和本地视频中读取数据,对数据中的人脸表情进行happy(高兴)、sad(悲伤)、feared(害怕)、angry(生气)、disgusted(困惑)、 surprise(惊喜)、nothing(无)八分类。并根据视频中的人脸实时统计出每种表情所占的比例。

基于AI的管廊智能运维
摘要:
基于管廊机器人拍摄的视频画面进行自动的积水、异物入侵、支架脱落、管线走线不规范、乱拉线缆等进行实时的检测并预警。 目前该系统已应用于西安沣西一期24公里的地下管网的自动运维,并在郑州管廊推行试点中。
多目标跟踪检测
摘要: